
Einstufung von Verbatims in Ebene 1 und 2: Tutorial
Verfasst von
Matthieu SAUSSAYE
Veröffentlicht
Offene Verbatims klassifizieren (Ebene 1 und 2) mit SmartInterview
Sobald die Daten erfasst sind, sei es über SmartInterview oder eine externe Datei, besteht der nächste Schritt darin, die offenen Antworten in nutzbare Code-Frames zu transformieren.
SmartInterview ermöglicht Ihnen:
Einen Code-Frame (1 oder 2 Hierarchie-Ebenen) zu definieren (bald 3)
Themen automatisch per KI mit benutzerdefinierten Anweisungen zu generieren
Die Anzahl der Codes pro Befragtem durch ein Regelsystem präzise zu steuern
Ein Trainings-Dataset zu importieren, um die Klassifizierung zu steuern
Eine Stichprobe vorab zu klassifizieren (Pre-classification) und die Ergebnisse zu korrigieren
Die vollständige Klassifizierung für alle Antworten zu starten
Die Qualität der Codes mit einer MECE-Korrelationsmatrix (mutually exclusive, collectively exhaustive) zu bewerten
Die Ergebnisse nach Excel zu exportieren
Die Ergebnisse auf dem Dashboard zu analysieren
Dieser Artikel erklärt Schritt für Schritt, wie Sie eine 1- oder 2-stufige Klassifizierung in der Plattform durchführen.
1. Datenquelle auswählen
Die Codierung akzeptiert zwei Quellen :
Quelle | Nutzung | Anwendungsfall |
|---|---|---|
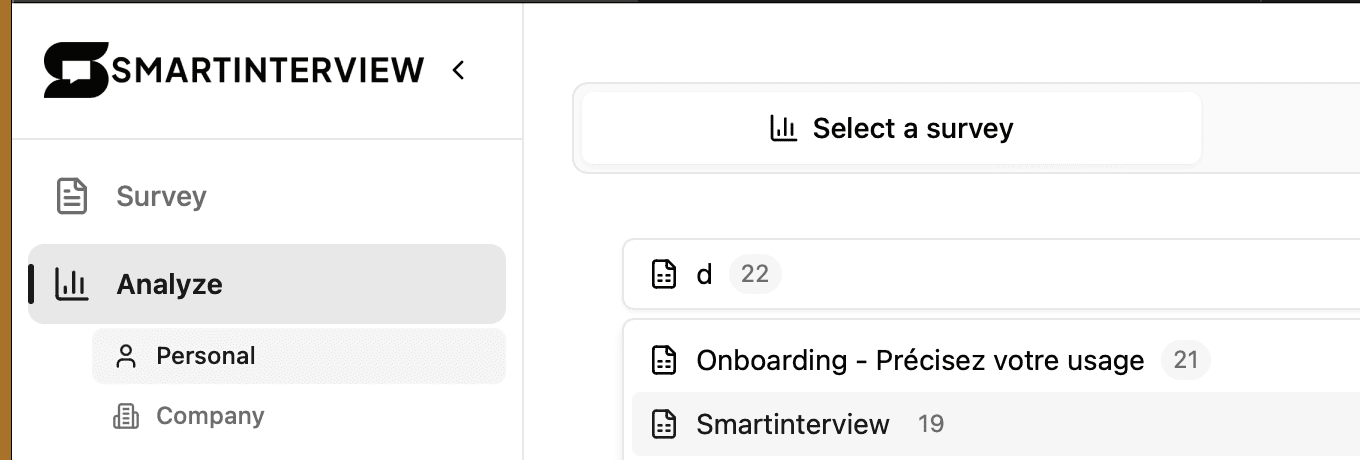
SmartInterview Umfrage | Wählen Sie eine bestehende Umfrage und dann eine offene Frage aus | Sie haben Antworten über SmartInterview gesammelt |
Excel-Datei | Importieren Sie eine Datei, die die Verbatims enthält | Sie haben Daten aus einem externen Tool |
Excel-Datei:
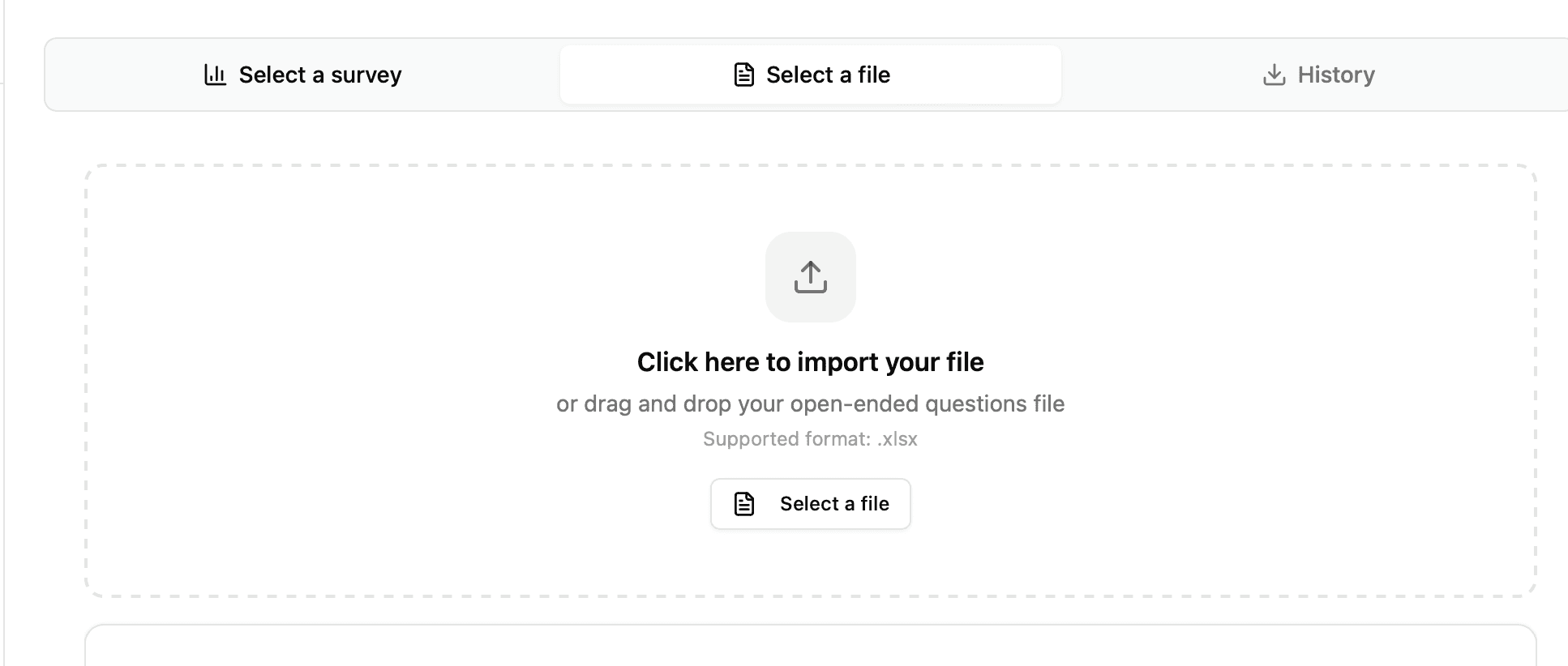
Umfrage:
Datei-Import: Spaltenauswahl
Beim Importieren einer Datei müssen Sie dem System Folgendes mitteilen :
Die Befragten-Spalte (eindeutige ID für jeden Befragten)
Wenn Ihre Datei keine ID enthält, wählen Sie "No column" : Das System nummeriert die Befragten automatisch von 1 bis N
Die Antwortspalte für die Klassifizierung (die Verbatims)
Tipp : Das System erkennt geläufige Spaltennamen automatisch (Respondent_ID, Serial, Réponses, Answer, etc.) anhand der Datei-Header.
[Screenshot: Spaltenauswahl in der Konfiguration]
2. Tiefe der Klassifizierung wählen
Tiefe 1 Ebene (nur L1)
Eine flache Liste von Hauptthemen. Jede Antwort wird einem oder mehreren Themen zugeordnet.
Use Case : Explorative Studien, erste schnelle Analyse, kurze Verbatims.
Tiefe 2 Ebenen (L1 + L2)
Hauptthemen (L1) mit zugeordneten Unterthemen (L2). Die Struktur ist hierarchisch : Jedes Unterthema gehört zu genau einem übergeordneten Hauptthema (Parent).
Use Case : Tiefgehendere Marktstudien, die eine feine Granularität erfordern, Unterscheidung von Nuancen innerhalb desselben Themas, Codierung gemäß Market Research-Standards.
In diesem Beispiel:
Ease of use → L1 (Hauptthema)
die Zeilen mit einer ID → L2 (Unterthemen)
3. Code-Frame definieren
Es gibt zwei Möglichkeiten, Ihren Code-Frame zu erstellen :
A - Einen Excel-Code-Frame importieren (wie im Beispiel)
B - Die KI die Themen generieren lassen.
Option A: Codes über Excel importieren
Wenn Sie bereits einen Code-Frame haben, importieren Sie ihn direkt.
Format für 1 Ebene
Eine Datei mit mindestens einer Spalte, die die Theme-Labels enthält :
ID | Label |
|---|---|
1 | Interface is intuitive |
2 | Ease of use |
3 | Performance is fast |
4 | App crashes |
5 | Nothing |
Format für 2 Ebenen
Die Datei muss L1 und L2 hierarchisch strukturieren. Das System erkennt die Spalten ID und Label automatisch anhand der Header.
Option 1 : Getrennte Spalten für die Ebenen (in einem Excel-Sheet):
L1 | L2 |
|---|---|
Ease of use | Interface is intuitive |
Ease of use | Navigation is confusing |
Ease of use | Easy to complete tasks |
Ease of use | Sensation is smooth |
Ease of use | The shape is nice |
Option 2 : Mit IDs und Parent_ID :
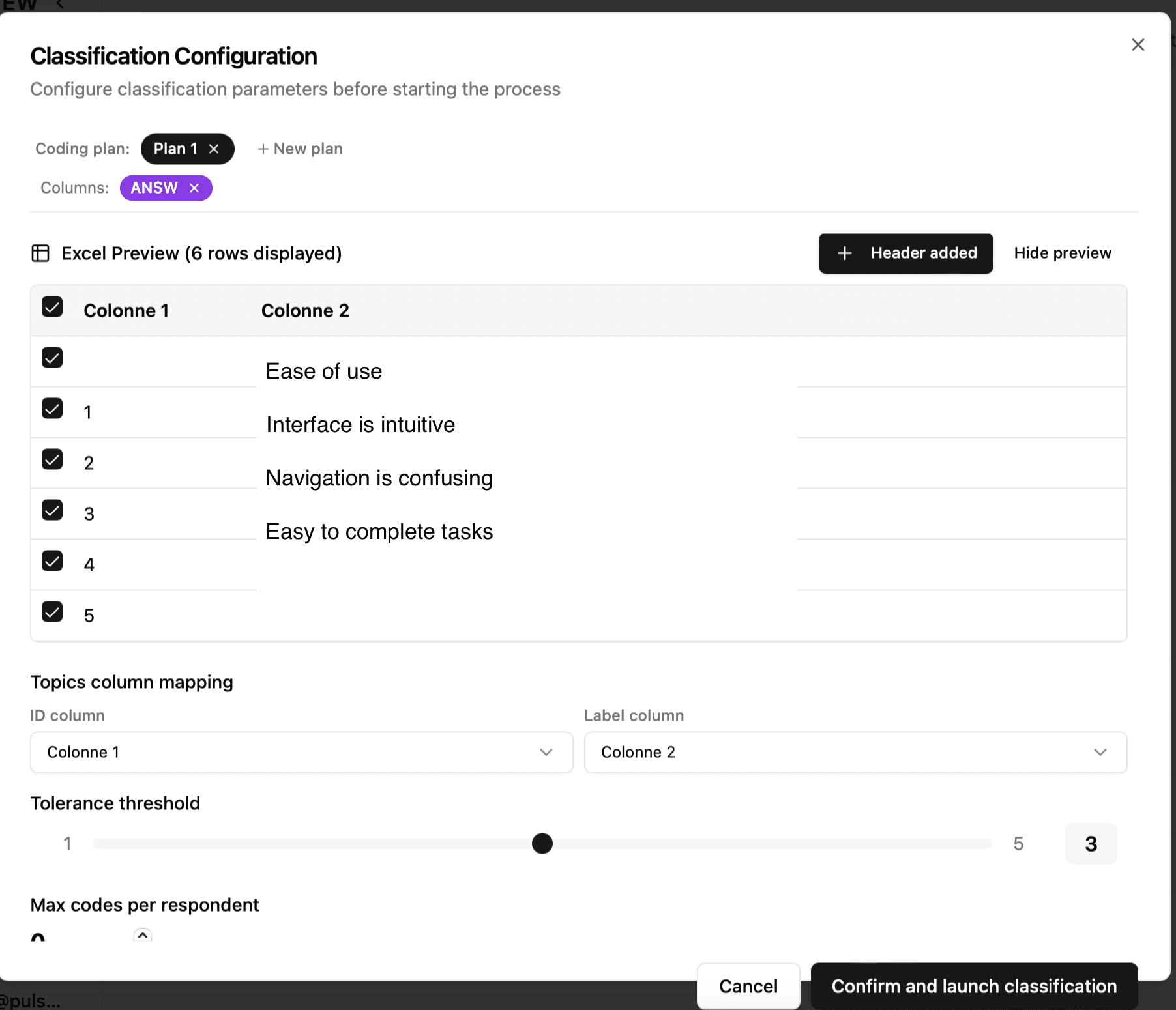
💡 Tipp : Sie müssen die Topics in einer separaten Tabelle Ihrer Excel-Datei speichern (z.B. ein Tab namens "Topics"). Das System fordert Sie auf, das Blatt auszuwählen, das die Codes enthält.
Vorschau und Filterung
Nach dem Import wird eine Vorschau des Code-Frames angezeigt mit :
Der Anzahl der erkannten Topics (wird automatisch aktualisiert)
Der Möglichkeit, nach Spalten zu filtern (nützlich, um bestimmte Kategorien auszuschließen)
Der Möglichkeit, einzelne Zeilen manuell auszuschließen
Option B: Codes durch KI generieren lassen
Wenn Sie keinen vordefinierten Code-Frame haben, analysiert die KI eine Stichprobe Ihrer Antworten und erkennt automatisch wiederkehrende Themen.
Wie es funktioniert
Das System zieht eine Stichprobe von bis zu 400 Antworten aus Ihrer Datei
Die KI identifiziert wiederkehrende Themen und formuliert sie in klaren Labels
Die Themen werden nach geschätzten Häufigkeiten (Frequenzen) sortiert (indikative Anzahl der betroffenen Befragten)
Die Themen werden automatisch nummeriert (sequenzielle IDs)
Eigene Anweisungen geben (Guidelines)
Sie können die Generierung steuern, indem Sie textuelle Anweisungen im Feld "Guidelines" eingeben :
Diese Anweisungen beeinflussen direkt :
Das für die Labels verwendete Vokabular
Die Granularität (mehr oder weniger Themen)
Die Analyseperspektive (sensorisch, emotional, funktional...)
Die Sprache der Labels
⚠️ Wichtig : Die Guidelines befinden sich in der Beta-Version. Sie eignen sich gut, um die Generierung zu steuern, die Ergebnisse können jedoch variieren. Überprüfen Sie die generierten Themen immer selbst.
Generierung im 2-Ebenen-Modus
Im 2-Ebenen-Modus umfasst der Prozess zwei Schritte :
Generierung der L1-Themen: Die KI identifiziert die Hauptthemen
Automatische Generierung der L2-Themen: Für jedes L1-Thema generiert die KI automatisch Unterthemen basierend auf den entsprechenden Antworten
L1-Themen, die noch keine Unterthemen haben, werden automatisch erkannt, und das System startet die Generierung der fehlenden L2-Themen, bevor die Klassifizierung beginnt.
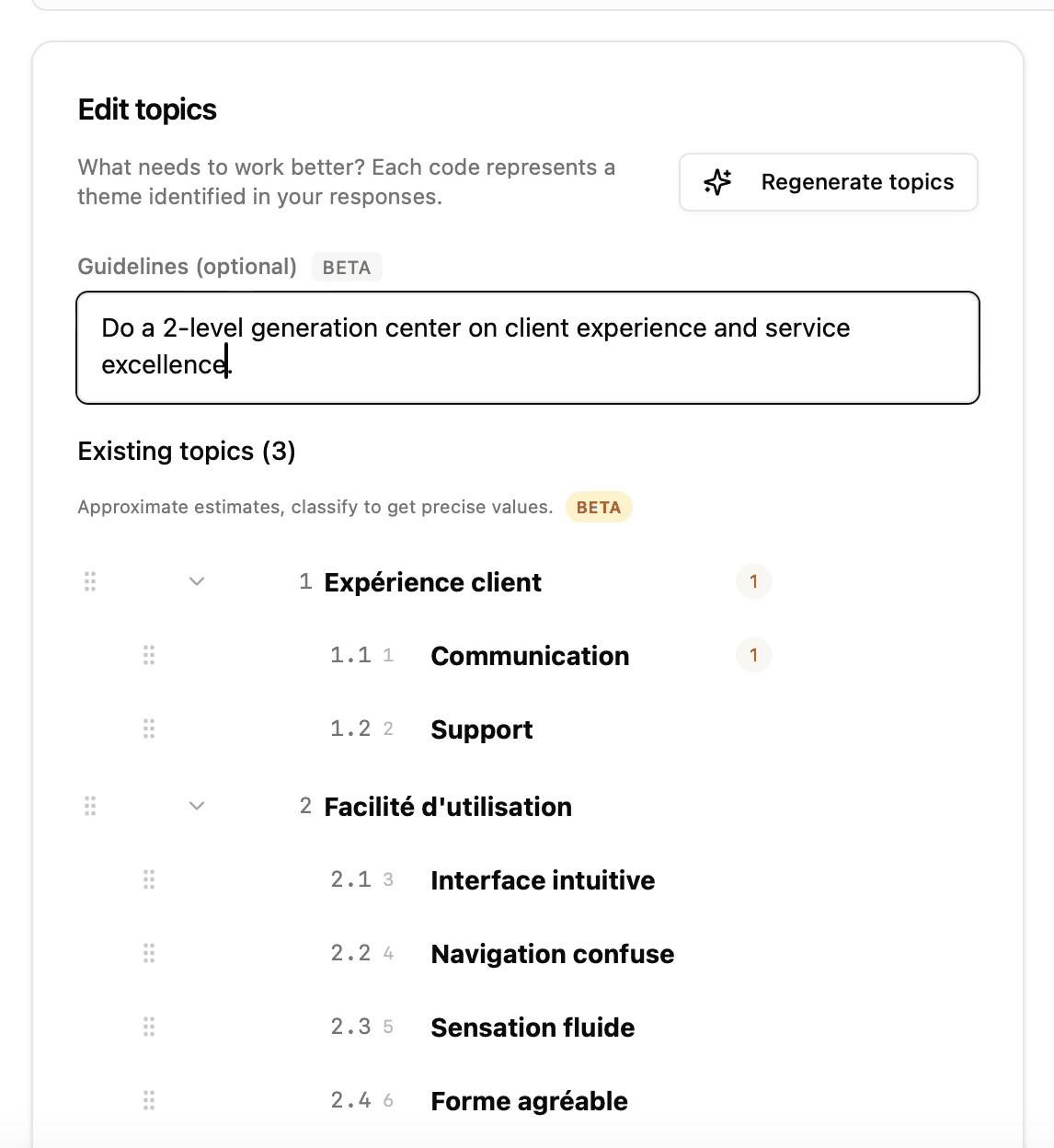
Code-Frame-Editor
Egal, ob importiert oder generiert: Die Themen erscheinen im Code-Frame-Editor (linkes Seitenpanel), wo Sie folgende Aktionen ausführen können :
Aktion | Wie |
|---|---|
Thema umbenennen | Klicken Sie auf das Label und bearbeiten Sie es direkt |
Thema löschen | Klicken Sie auf das Papierkorb-Symbol 🗑️ |
Thema hinzufügen | Klicken Sie auf die Schaltfläche + unten in der Liste |
Themen neu anordnen | Per Drag-and-Drop über das Griff-Symbol ≡ verschieben |
L2 ein-/ausklappen | Klicken Sie auf den Pfeil ▶ neben einem L1-Thema |
Themen neu generieren | Klicken Sie auf die Schaltfläche ✨, um die KI-Generierung neu zu starten |
L2-Themen eines Parents neu generieren | Klicken Sie auf ✨ neben einem bestimmten L1-Thema |
💡 Die geschätzten Häufigkeiten (die indikative Zahl neben jedem Thema) werden nach jeder Klassifizierung neu berechnet. Vor der ersten Klassifizierung stammen sie aus der Schätzung der KI während der Generierung.
4. Klassifizierungsregeln konfigurieren
Die Regeln steuern, wie viele Codes jedem Befragten zugeordnet werden können. Sie werden auf drei Ebenen angewendet : bei der Pre-Classification, auf die importierten Beispiele und bei der vollständigen Klassifizierung.
Regeln für Ebene 1
Parameter | Beschreibung | Standardwert |
|---|---|---|
Max Codes | Maximale Anzahl von Themen pro Befragtem | 0 (unbegrenzt) |
Beispiel : Mit Max Codes = 3 kann ein Befragter maximal 3 Themen erhalten, selbst wenn seine Antwort mehr Themen anspricht.
Regeln für Ebene 2
Im 2-Ebenen-Modus ermöglichen drei zusätzliche Parameter eine feine Steuerung :
Parameter | Interner Code | Beschreibung | Standardwert |
|---|---|---|---|
Max L1 | maxCodesL1 | Maximale Anzahl von Hauptthemen pro Befragtem | 0 (unbegrenzt) |
Max L2 | maxCodesL2 | Maximale gesamte Anzahl von Unterthemen pro Befragtem | 0 (unbegrenzt) |
Max L2 pro L1 | maxCodesL2PerL1 | Maximale Anzahl von Unterthemen pro Hauptthema (Parent) | 0 (unbegrenzt) |
Reihenfolge der Regelanwendung:
Max L1 : Begrenzt die Anzahl der Hauptthemen (Schritt 1)
Max L2/L1 : Begrenzt die Unterthemen pro Parent (Schritt 2, über Aufrufe)
Globales Max L2 : Endgültige Obergrenze nach Zusammenführung aller Unterthemen (Post-Processing)
💡 Tipp : Das Max L2/L1 ist besonders nützlich, wenn einige L1-Themen sehr breit gefächert sind und Gefahr laufen, alle Unterthemen an sich zu reißen. Mit Max L2/L1 = 2 kann beispielsweise jedes übergeordnete Thema maximal 2 Unterthemen beisteuern, was für eine ausgewogene Verteilung sorgt.
5. Ein Trainings-Dataset importieren (historische Daten) (optional)
Warum Beispiele importieren?
Ein Trainings-Dataset (oder few-shot examples) ermöglicht es, Beispiele für bereits codierte Verbatims zu zeigen. Diese Beispiele werden als Kontext gesendet, um jeden Batch der Klassifizierung anzuleiten.
Der Import wird empfohlen, wenn:
Themen sehr nuanciert oder nahe beieinander sind.
Sie Kontinuität innerhalb eines Projekts oder zwischen mehreren Projekten wünschen.
Sie spezifische Codierungskonventionen haben (z. B. müssen bestimmte Begriffe immer einem bestimmten Thema zugeordnet werden).
Sie eine bestehende Klassifizierung auf neue Daten reproduzieren möchten.
Die Pre-classification ohne Beispiele unbefriedigende Ergebnisse liefert.
Format der Trainingsdatei
Die Excel-Datei sollte wie folgt aufgebaut sein :
Answer | ANSW_1aCOMM1 | ANSW_2aCOMM2 | ANSW_3aCOMM3 | ANSW_4aCOMM4 | ANSW_5aCOMM5 |
|---|---|---|---|---|---|
L’interface reste fluide du début à la fin, très proche d’une application premium. | 21 | ||||
L’application est correcte, rien de particulièrement remarquable. | 18 | 207 | |||
Navigation très douce, quelques animations agréables | 18 | 207 | |||
Parfois un peu saccadé et certaines sections semblent mal optimisées. | 45 | 212 | 233 | 240 |
Das System erkennt Spalten mit Codes automatisch, indem es sie mit den in Ihrem Code-Frame definierten Themen abgleicht. Spalten, deren Werte mit bekannten Themen übereinstimmen, werden automatisch identifiziert.
⚠️ Limitierung : Es werden maximal 30 Beispiele gespeichert. Die Codes müssen mit denen übereinstimmen, die im ursprünglichen Code-Frame der neu importierten Dateien verwendet werden.
Überprüfung und Übersetzung
Jedes importierte Beispiel wird angezeigt mit :
Dem Text der Antwort (Verbatim)
Den Badges der zugeordneten Themen (mit Farbcodierung)
Einer Übersetzungsschaltfläche für die Sprachauswahl (Français, English, Deutsch)
Die Übersetzung ermöglicht es Ihnen, den Inhalt der Beispiele in Ihrer Arbeitssprache zu überprüfen, ohne die an die Klassifizierung gesendeten Originaldaten zu ändern.
6. Eine Stichprobe vorab klassifizieren (Pre-classification)
Was ist die Pre-classification?
Bevor Sie die Klassifizierung für den gesamten Datensatz starten, klassifiziert das System die ersten 30 Antworten als Test. Dies ist der wichtigste Schritt, um die Qualität Ihres Code-Frames zu validieren.
Die Pre-classification verwendet exakt denselben Algorithmus wie die vollständige Klassifizierung, jedoch auf einer kleineren Stichprobe für eine schnelle Überprüfung.
Was Ihnen die Pre-classification zeigt
Für jede Antwort sehen Sie :
Den vollständigen Verbatim-Text (mit Hervorhebung der Schlüsselwörter, die den Themen entsprechen)
Die zugeordneten L1-Badges (mit Farbcodierung)
Die zugeordneten L2-Badges (falls Tiefe = 2), gruppiert unter ihren L1-Parents
Eine Zusammenfassung : Anzahl der klassifizierten Antworten im Verhältnis zur Gesamtzahl
Ergebnisse korrigieren
Die Pre-classification ist interaktiv – Sie können jede Zeile manuell korrigieren :
Aktion | Geste | Wirkung |
|---|---|---|
Thema entfernen | Klicken Sie auf das Badge-Symbol × | Das Thema wird von dieser Antwort entfernt |
L1-Thema hinzufügen | Klicken Sie auf + neben den L1-Badges | Dropdown-Menü mit allen verfügbaren L1-Themen |
L2-Thema hinzufügen | Klicken Sie auf + neben den L2-Badges | Gefiltertes Dropdown-Menü: Nur Unterthemen der bereits zugeordneten L1-Themen werden angezeigt |
Thema suchen | Geben Sie den Suchbegriff im Menü-Suchfeld ein | Echtzeit-Filterung der verfügbaren Themen |
💡 Validierungsbereich : Alle Zeilen zwischen Ihrer ersten und Ihrer letzten Korrektur gelten als validiert. Sie werden blau hervorgehoben und dienen automatisch als Gold Standard/Beispiele für die vollständige Klassifizierung.
7. Vollständige Klassifizierung starten
Wann sollte die Klassifizierung gestartet werden?
Starten Sie die vollständige Klassifizierung, wenn :
Die Themen der Pre-classification Ihren Erwartungen entsprechen
Etwaige Korrekturen an den ersten 30 Zeilen vorgenommen wurden
Die Trainingsdaten importiert wurden.
Die Regeln (Max Codes) korrekt konfiguriert sind
Was im Hintergrund passiert
Die Antworten werden in Batches aufgeteilt
Jeder Batch wird an die KI gesendet mit:
Der Liste der verfügbaren Themen
Den Trainingsbeispielen (importiert + manuelle Korrekturen der Pre-classification)
Den Regeln für die konfigurierten Limits
Im 2-Ebenen-Modus :
Schritt 1 : L1-Klassifizierung für alle Batches
Schritt 2 : Für jedes zugewiesene L1-Thema erfolgt die L2-Klassifizierung pro Parent
Post-Processing : Anwendung des globalen L2-Limits (
Max L2)
Ergebnis
Nach der Klassifizierung sehen Sie :
Ein Erfolgsbanner : "Classification complete : N classified responses"
Die ersten 30 Antworten mit den zugewiesenen Codes (bearbeitbar)
Die importierten Beispiele (ausklappbarer Bereich, falls ein Trainings-Dataset verwendet wurde)
Die Korrelationsmatrix (siehe nächster Abschnitt)
8. Ergebnisse mit der Korrelationsmatrix bewerten
Das MECE-Prinzip
Ein qualitativ hochwertiger Code-Frame muss MECE sein :
Mutually Exclusive : Jedes Thema deckt einen eigenständigen Aspekt ab. Zwei Themen sollten nicht dasselbe beschreiben.
Collectively Exhaustive : Die Summe der Themen deckt alle Antworten ab. Kein Verbatim sollte ohne passenden Code bleiben.
Lesen der Co-Occurrence-Matrix
Die Matrix zeigt den Prozentsatz der Befragten, die gleichzeitig zwei Themen erhalten haben. Die Diagonale zeigt immer 100 % (ein Thema korreliert immer mit sich selbst).
Interface is intuitive (122) | App is fast (6) | Navigation is confusing. (14) | App crashes or freezes (28) | |
|---|---|---|---|---|
Interface is intuitive (122) | 100% | 33% | 21% | 0% |
App is fast (6) | 33% | 100% | 0% | 0% |
Navigation is confusing (14) | 21% | 0% | 100% | 0% |
App crashes or freezes (28) | 0% | 0% | 0% | 100% |
Wie die Matrix zu interpretieren ist
Signal | Wert | Bedeutung | Empfohlene Maßnahme |
|---|---|---|---|
🔴 Hohe Korrelation | 50% | Die beiden Themen überschneiden sich häufig: möglicherweise redundant | Themen zusammenführen oder Definitionen präzisieren |
🟠 Mittlere Korrelation | 20-50% | Die Themen sind verwandt, aber unterschiedlich: akzeptabel | Einige Antworten stichprobenartig prüfen |
🟢 Geringe Korrelation | < 20% | Die Themen sind gut mutually exclusive | Keine Änderung erforderlich |
⚪ Keine Korrelation | 0% | Die Themen treten nie gemeinsam auf | Perfekt für gegensätzliche Themen (z. B. "Nothing" vs. andere) |
⚠️ Geringe Fallzahl | (1-2) | Das Thema betrifft nur sehr wenige Befragte | Eventuell zu spezifisch; Zusammenlegung mit einem übergeordneten Thema erwägen / bei 1-Ebenen-Codierung entfernen |
💡 Stark korrelierende Zellen werden farblich hervorgehoben, um Probleme schnell zu erkennen.
Beispiel für eine Analyse
In der obigen Matrix :
App is fast × Interface is intuitive = 33% → Diese beiden Aspekte werden manchmal zusammen genannt. Das ist normal für ein digitales Produkt: Die Themen bleiben funktional verschieden.
Nothing × alles andere = 0% → Perfekt: Befragte, die nichts zu sagen haben, werden keinen anderen Themen zugeordnet.
Interface is intuitive (122) ist das dominante Thema: 122 Befragte von 232, also mehr als die Hälfte.
Auf Ergebnisse reagieren
Wenn die Matrix Probleme aufzeigt :
Klicken Sie auf "Back to codes", um zum Code-Frame-Editor zurückzukehren
Fügen Sie redundante Themen zusammen oder formulieren Sie mehrdeutige Definitionen um
Starten Sie die Klassifizierung neu; die Korrekturen an den ersten 30 Zeilen bleiben als Trainingsbeispiele erhalten (Schaltfläche "Re-classify with corrections")
Dieser iterative Zyklus aus Klassifizieren → Evaluieren → Anpassen → Neu-Klassifizieren ermöglicht es, schrittweise einen robusten und MECE-konformen Code-Frame zu erarbeiten.
9. Ergebnisse exportieren
Sobald die Klassifizierung validiert ist, klicken Sie auf "Download Excel", um eine strukturierte Datei zu erhalten :
Tabellenblatt | Inhalt | Beschreibung |
|---|---|---|
FilesQO | Klassifizierte Daten | Jeder Befragte mit Originaltext und zugewiesenen Codes (Spalten für L1 und ggf. L2) |
Topics | Code-Frame | Die vollständige Liste der Themen mit ihren IDs, hierarchisch geordnet |
Top Topics | Häufigkeitsanalyse | Die am häufigsten genannten Themen mit absoluten Fallzahlen und Prozentangaben |
Praktische Tipps
Wie viele Themen sollte man definieren?
Anzahl der Antworten | Empfohlene L1-Themen | Empfohlene L2-Themen |
|---|---|---|
< 100 | 5 – 10 | 2 – 4 pro L1 |
100 – 500 | 10 – 20 | 3 – 6 pro L1 |
500 | 15 – 30 | 5 – 10 pro L1 |
Wann sollte man 1 Ebene vs. 2 Ebenen nutzen?
Kriterium | 1 Ebene | 2 Ebenen |
|---|---|---|
Schnelles exploratives Ziel | ✅ | |
Erste grobe Datenanalyse | ✅ | |
Feine Granularität erforderlich | ✅ | |
Lange und detaillierte Verbatims | ✅ | |
Kurze Verbatims (< 20 Wörter) | ✅ |