

Classifier les verbatims de 1 et 2 niveaux : tutoriel

Written by
Matthieu SAUSSAYE
Published
Mar 11, 2026
Classifier des verbatims ouverts (niveau 1 et 2) avec smartinterivew
Une fois les données collectées, que ce soit via SmartInterview ou un fichier externe, l'étape suivante est de transformer les réponses ouvertes en codes thématiques exploitables.
Smartinterview permet de:
Définir un plan de codification (1 ou 2 niveaux de profondeur) (bientôt 3)
Générer automatiquement des thèmes via l'IA, avec des instructions personnalisées
Contrôler précisément le nombre de codes par répondants grâce à un système de règles
Importer un jeu d'entraînement pour guider la classification
Pré-classifier un échantillon et corriger les résultats
Lancer la classification complète sur toutes les réponses
Évaluer la qualité des codes avec une matrice de corrélation MECE (mutuellement exclusifs, communément exhaustifs)
Exporter les résultats en Excel
Analyser les résultats sur la dashboard
Cet article explique, étape par étape, comment réaliser une classification à 1 ou 2 niveaux dans la plateforme.
1. Choisir la source de données
La codification accepte deux sources :
Source | Usage | Quand l'utiliser |
|---|---|---|
Enquête SmartInterview | Sélectionnez une enquête existante, puis une question ouverte | Vous avez collecté des réponses via SmartInterview |
Fichier Excel | Importez un fichier contenant les verbatims | Vous avez des données provenant d'un outil externe |
Fichier excel:
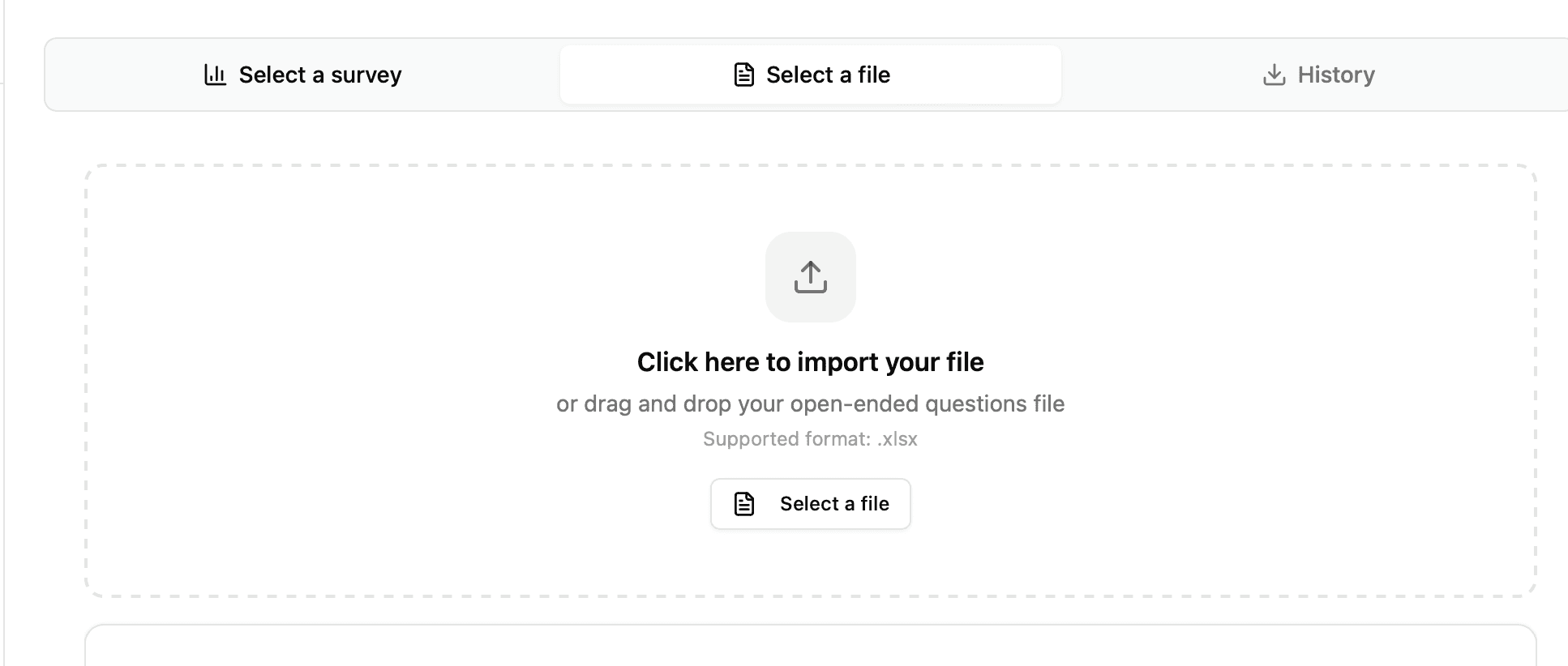
Sondage:
Import de fichier : sélection des colonnes
Lors de l'import d'un fichier, vous devez indiquer au système :
La colonne répondant (identifiant unique de chaque répondant)
Si votre fichier ne contient pas d'identifiant, choisissez "No column" : le système numérote automatiquement les répondants de 1 à N
La colonne de réponses à classifier (les verbatims)
Astuce : Le système détecte automatiquement les colonnes courantes (Respondent_ID, Serial, Réponses, Answer, etc.) à partir des en-têtes du fichier.
[Capture d'écran : sélection des colonnes dans la configuration]
2. Choisir la profondeur de classification
Profondeur 1 niveau (L1 uniquement)
Une liste plate de thèmes principaux. Chaque réponse est associée à un ou plusieurs thèmes.
Cas d'usage : études exploratoires, première analyse rapide, verbatims courts.
Profondeur 2 niveaux (L1 + L2)
Des thèmes principaux (L1) avec des sous-thèmes (L2) rattachés. La structure est hiérarchique : chaque sous-thème appartient à un seul thème parent.
Cas d'usage : études approfondies nécessitant une granularité fine, distinction des nuances au sein d'un même thème, codifications conformes aux standards market research.
Dans cet exemple :
Ease of use → L1 (thème principal)
les lignes avec un ID → L2 (sous-thèmes)
3. Définir le plan de codification
Vous avez par ailleurs; deux façons de créer votre plan de codes :
A - Importer un code-frame Excel (comme dans l'exemple)
B - Laisser l'IA générer les thèmes.
Option A : Importer les codes via Excel
Si vous disposez déjà d'un code-frame, importez-le directement.
Format pour 1 niveau
Un fichier avec au minimum une colonne contenant les libellés des thèmes :
ID | Label |
|---|---|
1 | Interface is intuitive |
2 | Ease of use |
3 | Performance is fast |
4 | App crashes |
5 | Nothing |
Format pour 2 niveaux
Le fichier doit structurer les L1 et L2 de manière hiérarchique. Le système détecte automatiquement les colonnes ID et Label à partir des en-têtes.
Option 1 : Colonnes de niveaux séparées (dans une feuille excel):
L1 | L2 |
|---|---|
Ease of use | Interface is intuitive |
Ease of use | Navigation is confusing |
Ease of use | Easy to complete tasks |
Ease of use | Sensation is smooth |
Ease of use | The shape is nice |
Option 2 : Avec identifiants et Parent_ID :
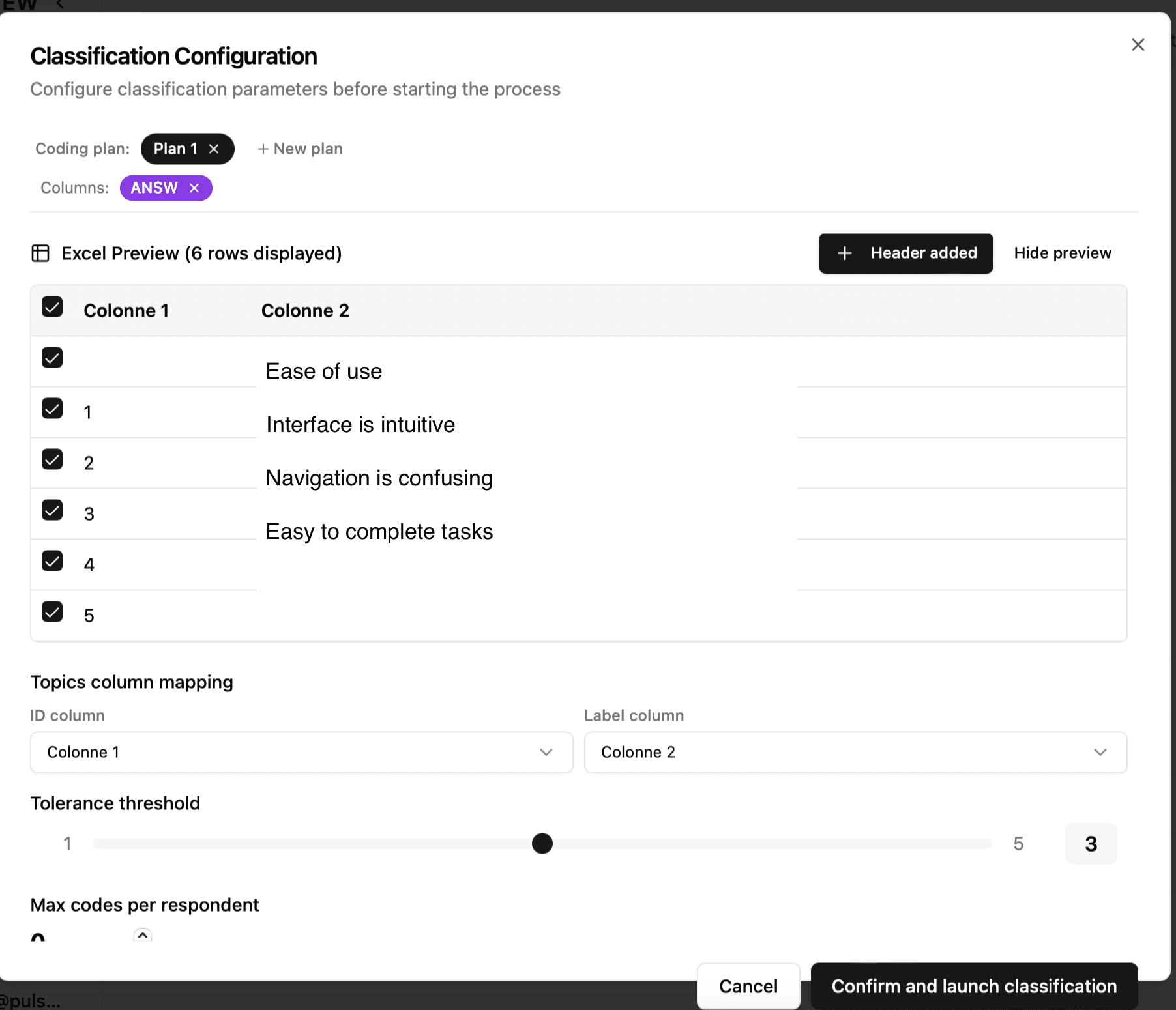
💡 Astuce : Vous devez stocker les topics dans une feuille séparée de votre fichier Excel (par ex. un onglet "Topics"). Le système vous propose de sélectionner la feuille contenant les codes.
Prévisualisation et filtrage
Après l'import, une prévisualisation du code-frame s'affiche avec :
Le nombre de topics détectés (mis à jour automatiquement)
La possibilité de filtrer par colonne (utile pour exclure certaines catégories)
La possibilité d'exclure manuellement des lignes individuelles
Option B : Générer les codes par l'IA
Si vous n'avez pas de plan de code préexistant, l'IA analyse un échantillon de vos réponses et découvre automatiquement les thèmes récurrents.
Comment ça marche
Le système échantillonne jusqu'à 400 réponses de votre fichier
L'IA identifie les thèmes récurrents et les formule en libellés clairs
Les thèmes sont triés par fréquences estimées (le nombre indicatif de répondants concernés)
Les thèmes sont automatiquement numérotés (ID séquentiels)
Donner des instructions personnalisées (Guidelines)
Vous pouvez guider la génération en fournissant des instructions textuelles dans le champ "Guidelines" :
Ces instructions influencent directement :
Le vocabulaire utilisé pour les libellés
Le niveau de granularité (plus ou moins de thèmes)
La perspective d'analyse (sensorielle, émotionnelle, fonctionnelle...)
La langue des libellés
⚠️ Important : Les instructions sont en version Beta. Elles fonctionnent bien pour orienter la génération, mais les résultats peuvent varier. Vérifiez toujours les thèmes générés.
Génération en mode 2 niveaux
En mode 2 niveaux, le processus comporte deux étapes :
Génération des L1: L'IA identifie les thèmes principaux
Génération automatique des L2: Pour chaque thème L1, l'IA génère automatiquement des sous-thèmes basés sur les réponses correspondantes
Les L1 qui n'ont pas encore de sous-thèmes sont détectés automatiquement, et le système lance la génération des L2 manquants avant de démarrer la classification.
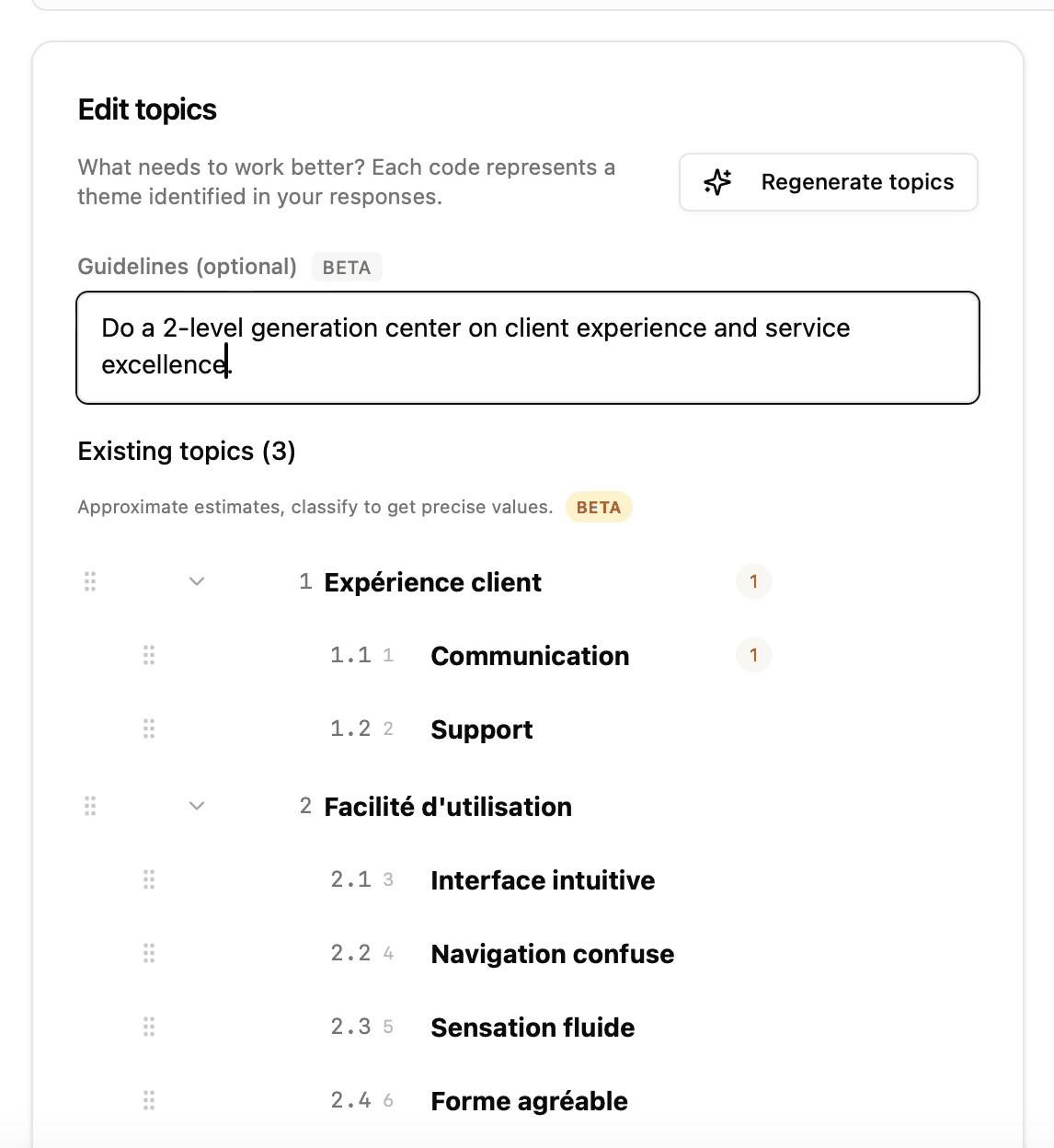
Éditeur de thèmes
Qu'ils soient importés ou générés, les thèmes apparaissent dans l'éditeur de thèmes (panneau latéral gauche), où vous pouvez :
Action | Comment |
|---|---|
Renommer un thème | Cliquez sur le libellé et éditez-le directement |
Supprimer un thème | Cliquez sur l'icône corbeille 🗑️ |
Ajouter un thème | Cliquez sur le bouton + en bas de la liste |
Réordonner les thèmes | Glissez-déposez via la poignée ≡ |
Déplier / replier les L2 | Cliquez sur la flèche ▶ à côté d'un thème L1 |
Re-générer les thèmes | Cliquez sur le bouton ✨ pour relancer la génération IA |
Re-générer les L2 d'un parent | Cliquez sur ✨ à côté d'un thème L1 spécifique |
💡 Les fréquences estimées (nombre indicatif affiché à côté de chaque thème) sont recalculées après chaque classification. Avant la première classification, elles proviennent de l'estimation de l'IA lors de la génération.
4. Configurer les règles de classification
Les règles contrôlent combien de codes peuvent être attribués à chaque répondant. Elles sont appliquées à trois niveaux : lors de la pré-classification, sur les exemples importés, et lors de la classification complète.
Règles pour 1 niveau
Paramètre | Description | Défaut |
|---|---|---|
Max codes | Nombre maximum de thèmes par répondant | 0 (illimité) |
Exemple : Avec Max codes = 3, un répondant ne pourra recevoir que 3 thèmes au maximum, même si sa réponse en mentionne davantage.
Règles pour 2 niveaux
En mode 2 niveaux, trois paramètres complémentaires permettent un contrôle fin :
Paramètre | Code interne | Description | Défaut |
|---|---|---|---|
Max L1 | maxCodesL1 | Nombre maximum de thèmes principaux par répondant | 0 (illimité) |
Max L2 | maxCodesL2 | Nombre maximum global de sous-thèmes par répondant | 0 (illimité) |
Max L2 par L1 | maxCodesL2PerL1 | Nombre maximum de sous-thèmes par thème parent | 0 (illimité) |
Ordre d'application des règles :
Max L1 : Limite le nombre de thèmes principaux (Passe 1)
Max L2/L1 : Limite les sous-thèmes par parent (Passe 2, par appels)
Max L2 global : Plafond final après fusion de tous les sous-thèmes (post-traitement)
💡 Conseil : Le Max L2/L1 est particulièrement utile lorsque certains thèmes L1 sont très larges et risqueraient de monopoliser tous les sous-thèmes. Par exemple, avec Max L2/L1 = 2, chaque thème parent ne peut contribuer que 2 sous-thèmes maximum, assurant une répartition équilibrée.
5. Importer un jeu d'entraînement (data du passé) (optionnel)
Pourquoi importer des exemples ?
Un jeu d'entraînement (ou few-shot examples) permet de montrer des exemples de verbatims déjà codifiés. Ces exemples sont envoyés comme contexte pour guider chaque lot de classification.
L'import est recommandé lorsque :
Les thèmes sont nuancés ou proches les uns des autres.
Vous souhaitez une continuité au sein d'un projet ou entre plusieurs projets.
Vous avez des conventions de codification spécifiques (ex: certaines expressions doivent toujours être classées sous un thème particulier)
Vous souhaitez reproduire une classification existante sur de nouvelles données.
La pré-classification sans exemples donne des résultats insatisfaisants.
Format du fichier d'entraînement
Le fichier Excel doit se présenter comme ceci :
Answer | ANSW_1aCOMM1 | ANSW_2aCOMM2 | ANSW_3aCOMM3 | ANSW_4aCOMM4 | ANSW_5aCOMM5 |
|---|---|---|---|---|---|
L’interface reste fluide du début à la fin, très proche d’une application premium. | 21 | ||||
L’application est correcte, rien de particulièrement remarquable. | 18 | 207 | |||
Navigation très douce, quelques animations agréables | 18 | 207 | |||
Parfois un peu saccadé et certaines sections semblent mal optimisées. | 45 | 212 | 233 | 240 |
Le système détecte automatiquement les colonnes contenant des codes en les comparant aux thèmes définis dans votre plan de codification. Les colonnes dont les valeurs correspondent à des thèmes connus sont automatiquement identifiées.
⚠️ Limite : 30 exemples sont conservés. Les codes doivent être les mêmes que ceux utilisés dans le plan de code initial du nouveau fichiers importés.
Vérification et traduction
Chaque exemple importé est affiché avec :
Le texte de la réponse (verbatim)
Les badges des thèmes attribués (avec code couleur)
Un bouton de traduction individuel avec choix de la langue (Français, English, Deutsch)
La traduction permet de vérifier le contenu des exemples dans votre langue de travail, sans modifier les données envoyées à la classification.
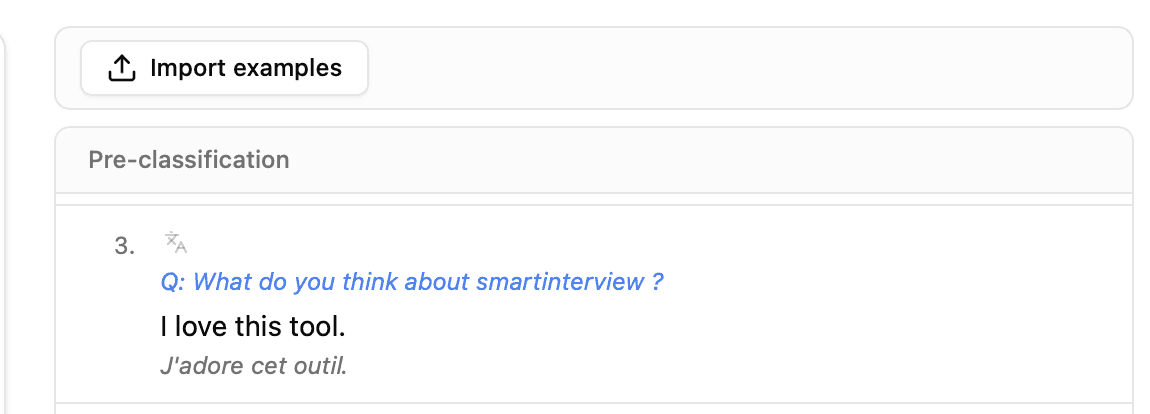
6. Pré-classifier un échantillon
Qu'est-ce que la pré-classification ?
Avant de lancer la classification sur l'ensemble des données, le système classe les 30 premières réponses à titre de test. C'est l'étape la plus importante pour valider la qualité de votre plan de codification.
La pré-classification utilise exactement le même algorithme que la classification complète, mais sur un échantillon réduit pour permettre une vérification rapide.
Ce que la pré-classification vous montre
Pour chaque réponse, vous voyez :
Le texte du verbatim (avec mise en surbrillance des mots-clés correspondant aux thèmes)
Les badges L1 attribués (avec code couleur)
Les badges L2 attribués (si profondeur = 2), groupés sous leurs parents L1
Un résumé : nombre de réponses classifiées sur le total
Corriger les résultats
La pré-classification est interactive vous pouvez corriger chaque ligne :
Action | Geste | Effet |
|---|---|---|
Retirer un thème | Cliquez sur le badge × | Le thème est retiré de cette réponse |
Ajouter un thème L1 | Cliquez sur + à côté des badges L1 | Menu déroulant avec tous les thèmes L1 disponibles |
Ajouter un thème L2 | Cliquez sur + à côté des badges L2 | Menu déroulant filtré : seuls les sous-thèmes des L1 déjà attribués sont proposés |
Rechercher un thème | Tapez dans le champ de recherche du menu | Filtrage en temps réel des thèmes disponibles |
💡 Zone de validation : Toutes les lignes entre votre première et votre dernière correction sont considérées comme validées. Elles sont surlignées en bleu et deviennent automatiquement des pour la classification complète.
7. Lancer la classification complète
Quand lancer la classification ?
Lancez la classification complète lorsque :
Les thèmes de la pré-classification correspondent à vos attentes
Les corrections éventuelles sont faites sur les 30 premières lignes
Les données d'entraînement sont importées.
Les règles (Max codes) sont correctement configurées
Ce qui se passe en arrière-plan
Les réponses sont découpées en lots (batches)
Chaque lot est envoyé à l'IA avec :
La liste des thèmes disponibles
Les exemples d'entraînement (importés + corrections de pré-classification)
Les règles de limites configurées
En mode 2 niveaux :
Passe 1 : Classification L1 sur tous les lots
Passe 2 : Pour chaque thème L1 attribué, classification L2 par parent
Post-traitement : Application du plafond global L2 (
Max L2)
Résultat
Après classification, vous voyez :
Un bandeau de succès : "Classification complete : N classified responses"
Les 30 premières réponses avec leurs codes attribués (modifiables)
Les exemples importés (section dépliable, si un jeu d'entraînement a été utilisé)
La matrice de corrélation (voir section suivante)
8. Évaluer les résultats avec la matrice de corrélation
Le principe MECE
Un plan de codification de qualité doit être MECE :
Mutually Exclusive : Chaque thème couvre un aspect distinct. Deux thèmes ne doivent pas décrire la même chose.
Collectively Exhaustive : L'ensemble des thèmes couvre toutes les réponses. Aucun verbatim ne devrait rester sans code pertinent.
Lire la matrice de co-occurrence
La matrice affiche le pourcentage de répondants ayant reçu simultanément deux thèmes. La diagonale est toujours à 100% (un thème est toujours corrélé avec lui-même).
Interface is intuitive (122) | App is fast (6) | Navigation is confusing. (14) | App crashes or freezes (28) | |
|---|---|---|---|---|
Interface is intuitive (122) | 100% | 33% | 21% | 0% |
App is fast (6) | 33% | 100% | 0% | 0% |
Navigation is confusing (14) | 21% | 0% | 100% | 0% |
App crashes or freezes (28) | 0% | 0% | 0% | 100% |
Comment interpréter la matrice
Signal | Valeur | Signification | Action recommandée |
|---|---|---|---|
🔴 Corrélation élevée | 50% | Les deux thèmes se chevauchent souvent: possiblement redondants | Fusionner les thèmes ou reformuler les définitions |
🟠 Corrélation moyenne | 20-50% | Les thèmes sont liés mais distincts: acceptable | Vérifier quelques réponses pour confirmer |
🟢 Corrélation faible | < 20% | Les thèmes sont bien mutuellement exclusifs | Rien à changer |
⚪ Corrélation nulle | 0% | Les thèmes ne coexistent jamais | Parfait pour des thèmes antagonistes (ex: "Nothing" vs les autres) |
⚠️ Faible effectif | (1-2) | Le thème concerne très peu de répondants | Peut-être trop spécifique envisager de fusionner avec un thème parent / ou enlever dans une codification à 1 niveau |
💡 Les cellules fortement corrélées sont mises en surbrillance colorée pour repérer rapidement les problèmes.
Exemple d'analyse
Dans la matrice ci-dessus :
App is fast × Interface is intuitive = 33% → Ces deux sensations sont parfois mentionnées ensemble. C'est normal pour un produit consommé par inhalation: les thèmes restent distincts.
Nothing × tout le reste = 0% → Parfait : les répondants qui n'ont rien à dire ne sont pas classés dans d'autres thèmes.
Interface is intuitive (122) est le thème dominant: 122 répondants sur 232, soit plus de la moitié.
Agir sur les résultats
Si la matrice révèle des problèmes :
Cliquez sur "Back to codes" pour revenir à l'éditeur de thèmes
Fusionnez les thèmes redondants ou reformulez les définitions ambiguës
Relancez la classification; les corrections apportées sur les 30 premières lignes sont conservées comme exemples d'entraînement (bouton "Re-classify with corrections")
Ce cycle itératif classifier → évaluer → ajuster → re-classifier permet d'atteindre progressivement un plan de codification robuste et MECE.
9. Exporter les résultats
Une fois la classification validée, cliquez sur "Download Excel" pour obtenir un fichier structuré :
Feuille | Contenu | Description |
|---|---|---|
FilesQO | Données classifiées | Chaque répondant avec son texte et ses codes attribués (colonnes L1 et L2 si applicable) |
Topics | Plan de codification | La liste complète des thèmes avec leurs identifiants, organisée hiérarchiquement |
Top Topics | Synthèse fréquentielle | Les thèmes les plus fréquents avec leurs comptages et pourcentages |
Conseils pratiques
Combien de thèmes définir ?
Nombre de réponses | Thèmes L1 recommandés | Thèmes L2 recommandés |
|---|---|---|
< 100 | 5 – 10 | 2 – 4 par L1 |
100 – 500 | 10 – 20 | 3 – 6 par L1 |
500 | 15 – 30 | 5 – 10 par L1 |
Quand utiliser 1 niveau vs 2 niveaux ?
Critère | 1 niveau | 2 niveaux |
|---|---|---|
Objectif exploratoire rapide | ✅ | |
Première analyse de données | ✅ | |
Granularité fine requise | ✅ | |
Verbatims longs et détaillés | ✅ | |
Verbatims courts (< 20 mots) | ✅ |